

Selenium is arguably the biggest player in test automation. No other rival tools have successfully defeated Selenium’s popularity. A lot of software and non-software organizations are using Selenium to automate their web applications.
The Need for Selenium
If you’re like us, regardless of whether you inherit your Selenium framework or you’re tasked to build a brand new one, you’ll probably wonder “is my Selenium framework good enough?” This article will help you answer that question by highlighting the 6 signs that your Selenium framework is bad.
- Updating tests is a pain in the… bottom
- Test failures are cryptic
- Test execution is slow
- Hard-coded locators for dynamic elements
- Lack of mobile testing
- Not wiring your Selenium tests into the CI/CD pipeline
Sign #1. Updating tests is a pain in the… bottom
Symptom
At the beginning, your scripts are small. Script maintenance seems easy. But as time flies, test suites grow exponentially. Not just you but, your team members continuously add more code lines to your codebase. Then there comes a point that your Selenium code becomes unmaintainable.
You’ll notice this when you see too many similar code fragments and too many duplicated locators. When the app’s GUI changes albeit slightly, you’ll have to walk through the whole codebase to update and make it run again.
For example, you have 50 different tests that are using the same locator. With any change to that element, you need to change all 50 tests. Imagine that you have hundreds of those test cases. Or worse, you have thousands of them like we’re currently having in our projects. Updating the whole codebase would become impossible.
What can I do about it?
Luckily, the solution for this common problem is already out there: Page Object Model (POM) design pattern. POM has become popular in Test Automation for reducing duplicated code and enhancing code maintenance.
The below example shows a test case written in the POM style. “homePage” and “registerPage” are page objects.
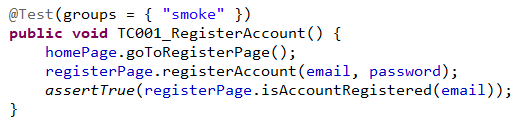
A page object conceptually represents a page or a part of a page. A page object can contain locators to identify web elements on that page as well as methods to interact with that page like “search”, “login”, or “register account.”
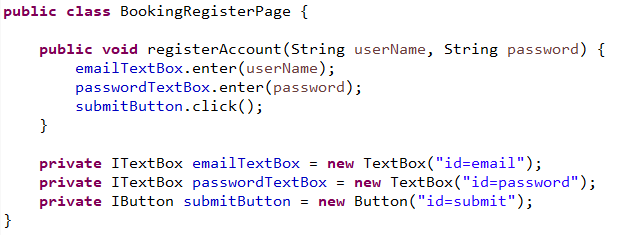
Page objects can be reused in any tests. When any changes happen to those elements or methods, you just need to update those elements and methods once inside the page object, instead of updating thousands of different tests.
Sign #2. Hard to investigate Selenium test failures quickly
Symptom
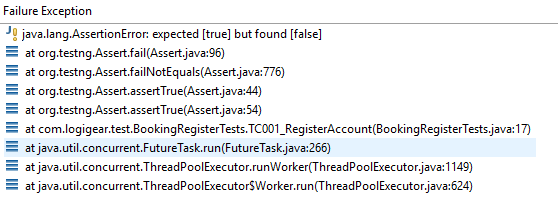
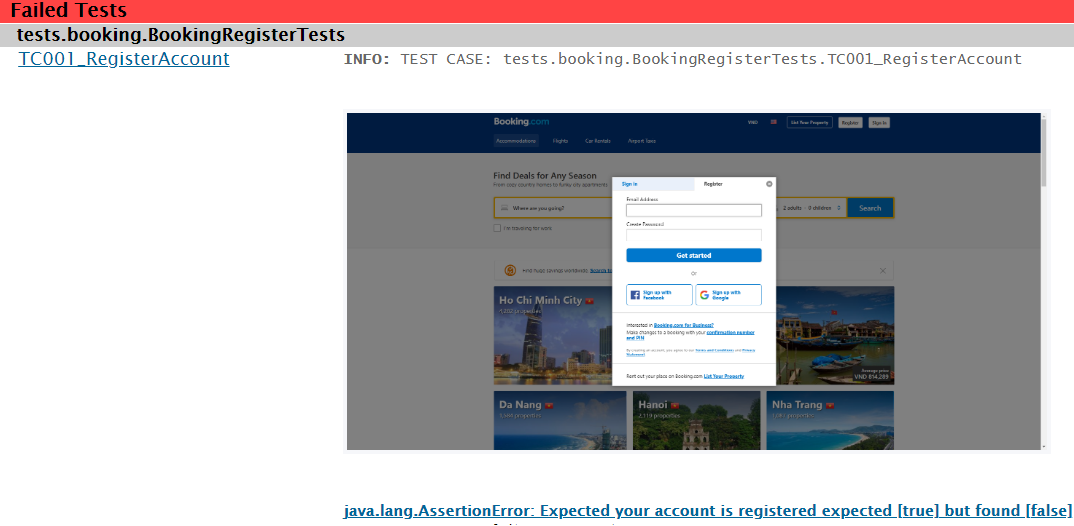
Selenium helps you automate a web application end-to-end. However, when a test fails, investigating the root cause of why the failure happened can be a real challenge. Your test framework might report a vague message such as expected [true] but found [false].
For example, when you execute the test case described in Figure 1, we’ll receive the following mysterious error.
If you’ve invested in a good result reporting mechanism for your assertions, you may get better messages like Expected your account is registered (sic).
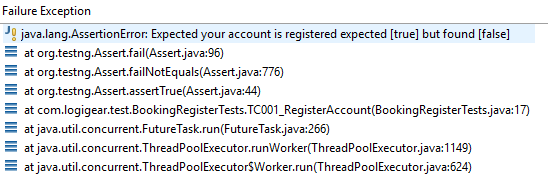
But if the new account wasn’t registered, what went wrong? What should we do to fix it? To answer this question, we might have to re-run the test and observe the live execution to understand what was happening. That’d take a lot of time for re-executing and figuring out the root cause.
What can I do about it?
Take screenshots – Most test failures can be investigated quickly with some additional visual aids. You can see what was happening with the app under test when the test failed such as a UI control was not found, the page was blank or similar details.
Inspect the HTML source code – Sometimes your page looks correct, but it actually has a problem under the hood. In this case, you can use the Selenium method getPageSourceand export the current HTML source to your result report.
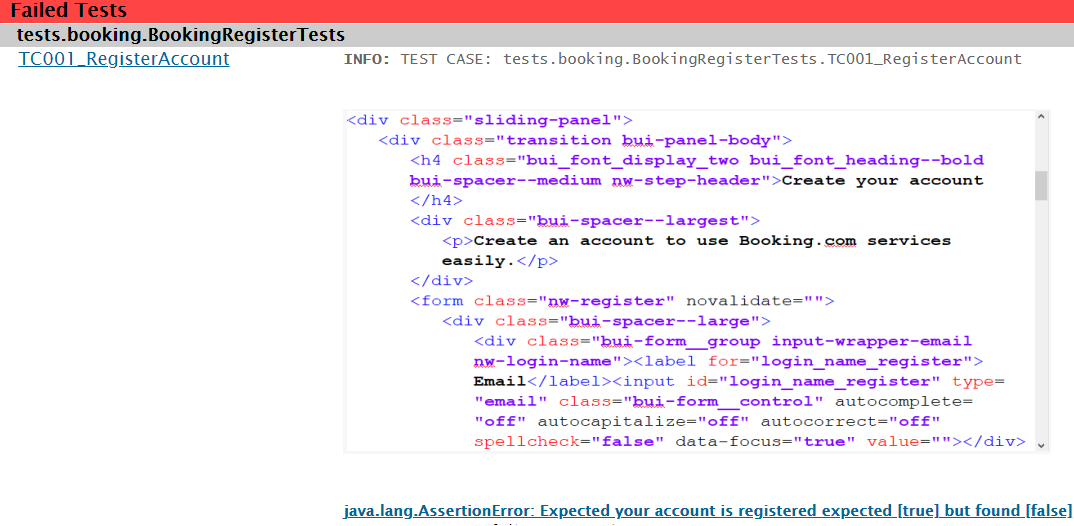
With some familiarity with HTML, you can use this HTML snapshot to figure out what was missing on the GUI that caused the test to fail.
Sign #3. Test execution is slow
Symptom
As our test project grows, we’ll quickly stumble upon scalability problems. In DevOps, tests will be run per code commit and build statuses need to be reported back to developers and testers in the blink of an eye. If it takes a couple of days just to execute a smoke test suite consisting of only several end-to-end test cases, then you have a problem.
What can I do about it?
Parallel and distributed test execution – It’s a common practice to parallelize and distribute test execution to reduce execution time using Selenium Grid. Parallelizing test execution means you run the same test suite on different machines against different browsers in parallel. The goal is to ensure that your web app runs smoothly across browsers. Therefore, we can also call it “cross-browser testing”.
On the other hand, distributed test execution means you dispatch multiple test suites to multiple machines so that the whole execution workload is shared thereby cutting down test execution time. Note that unlike cross-browser testing, each test case in this scenario only runs once.
Imagine that we have 50 tests and each test takes 2 minutes to run. Running them sequentially on one machine will take 100 minutes. However, if we spin up 50 virtual machines, distributing 50 tests to those machines to run in parallel will only cost 2 minutes for the entire batch.
In reality, the numbers differ a bit. From my experience, I have reduced the execution time of a thousand test cases from 10 hours to only 1 hour by spreading the workload to 20 machines. I can probably optimize it more but the 10x ratio is good enough now.
You should take advantage of Selenium Grid too. It’s a big mistake not to. To get started, check out the Selenium Grid guide here.
Optimize the speed of locating web elements – Locators are not created equal. Some locator types are faster for Selenium to parse and process. Some are slower. When you’re building a locator for an element, start with the fast locator types. Only if the faster locator cannot uniquely identify the web element, try a slower locator type. The recommended order is as below:
- ID
- Name
- CSS
- XPath
I recommended the above order because I’ve already measured the performance of them all. In my experiment, I tried to locate the [Search] textbox on www.booking.com using the above locator types.

The table below shows the time it takes to locate that [Search] text box. Note that for each locator type, I ran the measurement three times and averaged the results. The unit is millisecond.
| Browser | ID | Name | CSS | XPATH |
| Chrome | 38 | 40 | 43 | 50 |
| Firefox | 40 | 41 | 43 | 55 |
Some might say that a few-millisecond difference is negligible. However, I argue the opposite. Let’s say you currently use XPath to locate and interact with web elements. If you can convert all of your locators from XPath to ID, your test execution is now 24% faster on Chrome and 27% faster on Firefox. That’s some significant improvement.
Pro tip: You can cut down your locator building time by half using a free tool called POM Builder. It’s a Chrome extension that recommends the optimal locator for an element. You can use the recommended ID, name, CSS selector, or XPath in your Selenium and Protractor tests.
Don’t use hard sleep – The problem with hard sleep is that your test will pause and wait for a fixed amount of time. For example, if you have a sleep set for 10 seconds to wait for the web element to appear, your test pauses for 10 seconds regardless of the fact that the object you’re waiting for displays in 3 seconds. In this case, you should use Explicit Waits or Fluent Wait instead of Implicit Wait.
Sign #4. Hardcoded locators for dynamic elements
Symptom
Some of the web elements on your application are dynamic. That means the front-end will format and display different data depending on the backend. So when you open up a Selenium framework and you see hard-coded locators for dynamic elements, you can safely conclude that the framework has room for improvement.
For example, we have a table showing information about users like Last Name, First Name, and Email like below.
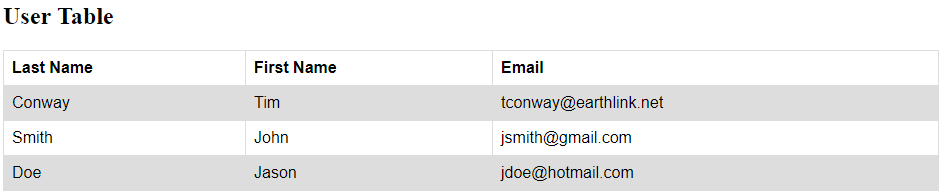
Currently, we have three users. Our automated test will try adding one more user and verify whether the newly created user is added to the table. The User Table after adding one new user looks like below:
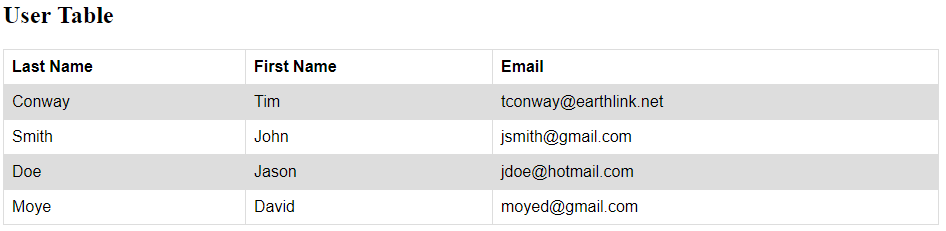
Some novice automation engineer might use the below locators to locate the elements we want to verify.
| Field | Locator |
| First Name | //table/tbody/tr/td[1][text()=’Moye’] |
| Last Name | //table/tbody/tr/td[2][text()=’David’] |
| //table/tbody/tr/td[3][text()=’moyed@gmail.com’] |
These are bad locators since ‘Moye’, ‘David’, and moyed@gmail.com are all changeable data. What if we want to add ‘John’, ‘Smith’, and smithj@gmail.com instead?
What can I do about it?
If an element’s attributes like ID, name and value change per every page refresh or page interaction, we need to handle the dynamic elements using dynamic XPath or CSS selector. That means we have to replace every bit of hard-coded data by variables.
Continuing with the above User Table example, it is better if we use a dynamic locator which can catch more than one of the similar UI Elements. I’d suggest we replace the above locators by this one:
| //table/tbody/tr/td[text()=’<Last Name>‘]/following-sibling::td[text()=’<First Name>‘]/following-sibling::td[text()=’<Email>‘] |
<Last Name>, <First Name> and <Email> are placeholders of dynamic values that will be passed in at run time. Although this locator returns only one element (the Email cell), it only does so successfully if the Last Name and First Name cells are also available and they contain the correct values.
Sign #5. Not wiring your Selenium tests into the CI/CD pipeline
Symptom
Many software development companies have been applying Continuous Integration and Continuous Deployment with great success. If your company has a CI/CD pipeline in place and you’re not integrating your Selenium framework with that CI/CD pipeline, you’re lagging behind.
What can I do about it?
Below are the steps that you can take to integrate your Selenium framework with a CI/CD pipeline.
- Select the browsers that the tests will be executed on, e.g. Chrome, Firefox, Edge, etc.
- Pick your programming language of choice, e.g. Java, Javascript, Python, etc.
- Decide which unit testing framework you want, e.g. JUnit, TestNG, etc.
- Create the tests
- Run the tests locally
- Create and configure a CI/CD job to control and execute your tests
- Schedule the job in your CI/CD tool (e.g. Jenkins, Bamboo, etc.), something similar to the below trigger.

A useful reference link: https://www.softwaretestingmaterial.com/selenium-continuous-integration/
Sign #6. Lack of Mobile testing
Symptom
Smartphones have become an important tool in technology with universal applications for both consumers and businesses. According to Bizness Apps, there are about “8 million apps in Google Play store and 2.2 million apps in the Apple App store. Those apps are serving over 3.5 billion mobile users in the world.”
So as web app developers or testers, we have to ensure that our apps work smoothly on mobile devices to meet the growing demand of the mobile-first world. Mobile web applications need to be extremely stable, secured, and simple.
But as you already know, Selenium can only help you drive web apps running on desktop browsers. Our hands are tied when we need to execute tests on mobile devices running iOS or Android.
What can I do about it?
We got a solution: Appium. Appium is an open-source Test Automation library that supports mobile web apps and native apps on many different iOS and Android devices. So a good Selenium framework should integrate with Appium right from the beginning.
I’ll write more about how to integrate with Appium in the future. Basically, once you already architect your Selenium framework well enough, integrating with Appium is simply a matter of creating a new iOSDriver or AndroidDriver using the Factory design pattern. Afterward, your test cases will interact with the iOS/Android devices through the Appium Server like below.
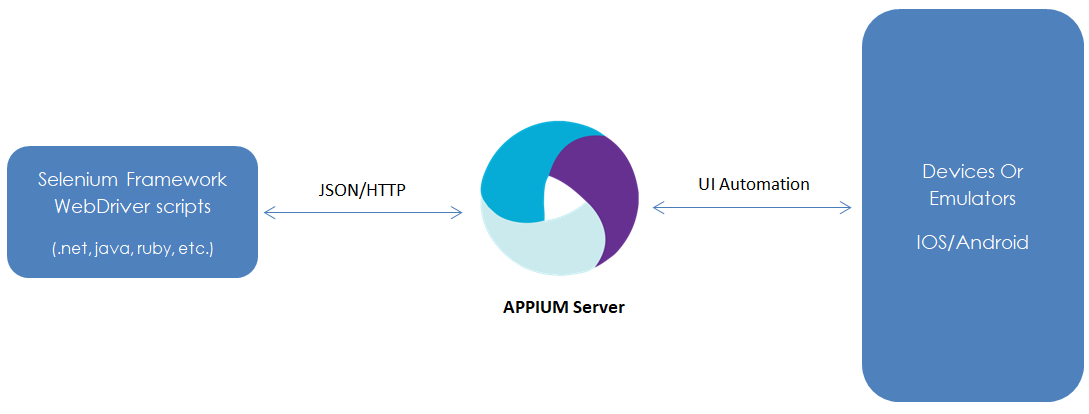
To learn more about architecting a good Selenium framework that can integrate with Appium from the beginning, check out this article.
Some more best practices for Selenium
My own experience of building quite a number of Selenium frameworks shows that every test team should establish some guidelines and best practices before kicking off a new Selenium project. Besides the best practices above, I’m listing below some more tips and tricks.
- Write data-driven tests instead of executing one test repeatedly
- Separate your test and your Test Automation framework
Conclusion
We’ve gone through the signs that reveal a BAD Selenium framework and the actions that we can take to improve our Selenium framework. Hopefully, you could take home some insights that are useful for improving the testing of your web applications. If you need help with building a better Selenium framework, LogiGear can help. Check out our selenium automation solutions on logigear.com today.
